
Modern businesses generate data continuously, application logs, payment events, sensor readings, clickstreams, and operational telemetry. Traditional batch analytics processes this data in scheduled intervals, which is useful for reporting but too slow for decisions that must happen now. Real-time analytics aims to process events as they arrive, convert them into metrics or signals, and trigger actions while the data is still fresh. For professionals exploring data analytics courses in Hyderabad, understanding stream processing is increasingly important because many analytics roles now touch near-real-time pipelines, not just dashboards and offline reporting.
What Stream Processing Really Means
Stream processing is an architectural approach where data is handled as an unbounded flow of events rather than a fixed dataset. Instead of waiting for a nightly job, a stream processor evaluates each event (or micro-batch of events) and updates results continuously.
Two ideas make stream processing different from conventional ETL:
Event time vs processing time
- Event time is when something actually happened (for example, when a user clicked “Pay”).
- Processing time is when your system received and processed the event.
In real systems, events can arrive late or out of order due to network delays or retries. Stream engines address this using watermarking, buffering, and “allowed lateness” rules.
Windows and aggregations
Many real-time metrics are calculated over windows: last 10 seconds, last 5 minutes, rolling hourly totals, or daily uniques. Windowing is central to stream processing because it turns raw event flows into stable, usable business signals.
A Practical Reference Architecture for Real-time Analytics
A reliable real-time analytics system typically has five layers. Even if implementations vary, the responsibilities remain the same.
1) Data ingestion
Events originate from web and mobile apps, backend services, IoT devices, or third-party systems. Good ingestion practices include consistent event naming, versioned schemas, and a clear approach to personally identifiable information (PII) collection.
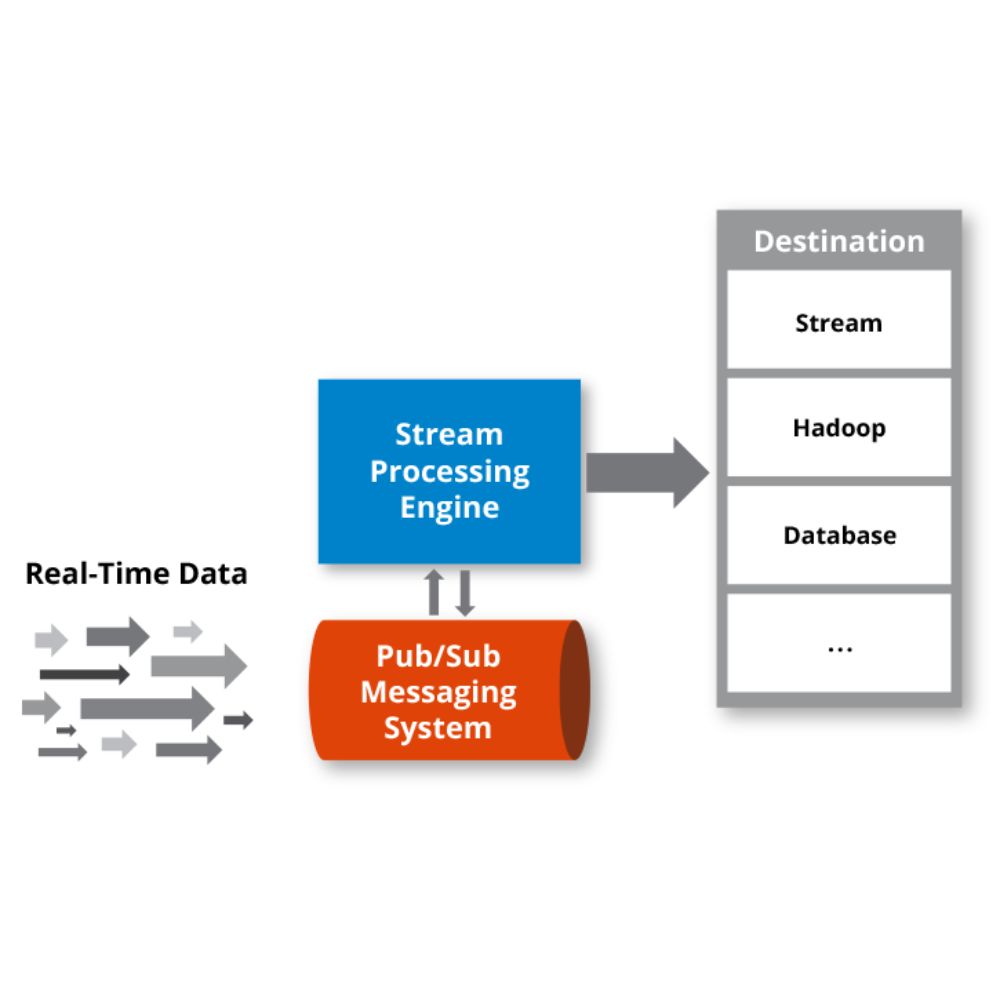
2) Messaging and buffering
A durable message layer absorbs spikes and decouples producers from consumers. This prevents a traffic surge from bringing down analytics processing. It also allows multiple downstream consumers, fraud checks, operations monitoring, and experimentation analytics, to read the same event stream independently.
3) Stream processing engine
This is where transformation, enrichment, joins, and aggregations happen. Common tasks include:
- filtering noisy events and standardising fields
- joining events with reference data (such as product catalogues or customer tiers)
- calculating windowed metrics (conversion rate, drop-off rate, error rate)
- detecting patterns (sudden spikes, repeated failures, unusual sequences)
For those taking data analytics courses in Hyderabad, this is the layer where analytics thinking meets engineering discipline: you define what “truth” means in motion, not just in a static table.
4) Serving and storage
Processed outputs must be queryable. Typical destinations include:
- OLAP stores for fast analytical queries
- time-series databases for monitoring metrics
- search indexes for event exploration
- caches for low-latency dashboards
The goal is to make results accessible to BI tools, alerting systems, and applications.
5) Observability and operations
Real-time systems need continuous monitoring. Track lag, throughput, error rates, late events, and resource usage. Without observability, issues remain hidden until business metrics become unreliable.
Choosing the Right Stream Engine: Key Evaluation Criteria
Stream processing tools differ in capabilities and operational complexity. Rather than choosing based on popularity, evaluate based on requirements.
Processing guarantees
- At-least-once: an event might be processed more than once (requires idempotent sinks or deduplication).
- Exactly-once: results remain correct even under failures and retries, but may be more complex to operate.
If you are computing financial totals, inventory, or compliance-sensitive metrics, correctness is usually worth the added complexity.
Stateful processing
Real-time analytics often needs state, counts, rolling averages, sessions, and “last seen” values. Engines vary in how they manage state, checkpoint it, and recover after failures.
Windowing sophistication
If you need complex windows (session windows, sliding windows, custom triggers), choose an engine that treats time semantics as a first-class feature, not an afterthought.
Integration and team skills
A good architecture is one your team can operate confidently. Consider learning curve, community maturity, deployment patterns, and the existing ecosystem in your organisation.
Data Quality and Governance in Motion
Real-time analytics fails silently if quality is not engineered into the pipeline. Three practices reduce risk:
Schema discipline
Use versioned schemas and enforce compatibility rules. This prevents upstream changes from breaking downstream jobs unexpectedly.
Handling duplicates and late events
Retries are normal in distributed systems. Plan for duplication and delayed delivery. Deduplication keys, idempotent writes, and clear lateness policies protect metric accuracy.
Privacy and access control
Streaming data often contains sensitive fields. Apply masking, tokenisation, and role-based access at the earliest stage possible. This is especially relevant for teams building customer analytics or payment monitoring, and it’s a topic frequently included in data analytics courses in Hyderabad focused on production-grade data practices.
Conclusion: Building for Immediate Insight Without Losing Trust
Real-time analytics is not just about speed. It is about delivering fast, correct, and explainable insights from data packets as they are generated. A strong architecture separates ingestion, buffering, processing, serving, and observability so each layer can scale and fail safely. Start with a narrow use case, such as live error monitoring, checkout funnel tracking, or operational alerts, then mature your pipeline with better time semantics, governance, and reliability practices. With the right foundations, stream processing becomes a dependable decision engine rather than a fragile, always-on experiment, and the skills translate well for anyone advancing through data analytics courses in Hyderabad and aiming to work on modern data platforms.